Математический анализ тенниса: как я создал предиктивный движок
Прогнозирование исходов в спорте - это всегда борьба с хаосом. В теннисе классические модели часто дают сбои, потому что не учитывают текущую форму игрока, тип покрытия корта, усталость и историю личных встреч (H2H). Я решил разработать собственный гибридный R&D-движок предиктивной аналитики, который объединяет машинное обучение и экспертные корректировки в реальном времени.
Зачем это нужно и в чем сложность
Идея была простая: сделать систему сравнительного анализа теннисистов перед матчем, которая считает математическую вероятность победы. Но спорт - штука субъективная. Если полагаться только на сухие цифры рейтингов, модель будет ошибаться на аномальных матчах. Например, когда фаворит играет на неудобном для себя покрытии или просто устал после затяжного турнира.
В итоге я пришел к гибридной схеме. Мой движок динамически балансирует веса факторов:
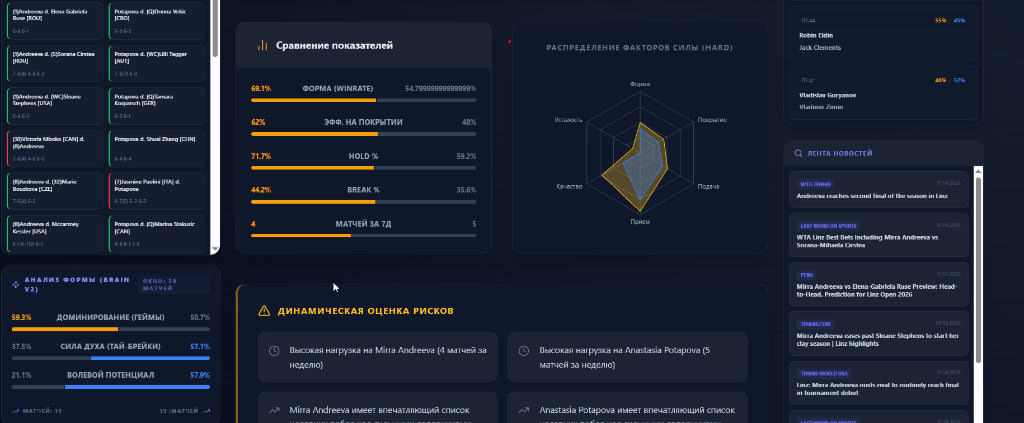
- Машинное обучение - [секретно]%: дает базовую вероятность победы на основе глобальной статистики.
- Текущая форма (последние 10 матчей) - **%: оценивает игровой тонус в моменте.
- Винрейт на покрытии (Surface Winrate) - **%: важнейший фактор, ведь физика игры на грунте, траве и харде абсолютно разная.
- История личных встреч (H2H) - **%: учитывает психологическое доминирование одного игрока над другим.
- Статистика геймов (Hold/Break) - **%: показывает эффективность подачи и приема.
- Качество оппозиции (Quality Wins) - **%: набранные очки силы на основе силы обыгранных соперников.
Если у игроков мало данных (например, это матч молодой лиги ITF), система автоматически снижает вес экспертной логики и на 85% доверяет обобщающей силе ML-модели, чтобы избежать ошибок из-за нехватки статистики.
Более 80 версий модели и глубокие признаки
Я провел огромную работу над признаками (Feature Engineering) и обучил более 80 различных версий модели на исторических данных. Чтобы научить систему видеть скрытые тренды, я написал парсер теннисных счетов. Он вычисляет глубокие метрики:
- Dominance Ratio (DR): отношение выигранных геймов к общему количеству. Это показывает реальное доминирование на корте, даже если счет по сетам был равным.
- Clutch Factor (Тай-брейки): процент побед в решающих геймах. Показывает ментальную стойкость игрока.
- Волевой потенциал (Comebacks): процент выигранных матчей после поражения в первом сете.
Борьба с асимметрией и учет усталости
В процессе тестов я столкнулся с тем, что ML-модели чувствительны к порядку ввода данных (Игрок 1 / Игрок 2). Чтобы решить эту проблему, я внедрил симметричное усреднение (Symmetry Correction). Скрипт делает два прогноза, меняя игроков местами, и считает итоговую вероятность по формуле:
P_final = (P_normal + (1.0 - P_swapped)) / 2.0
Также я добавил динамический штраф за физическое истощение (Fatigue Penalty). Скрипт анализирует количество сыгранных матчей за последние 7 дней и срезает шансы по формуле:
Fatigue = min(0.05, MatchesLast7Days * 0.02)
Результаты исторических тестов
Для проверки работоспособности я провел бэктест на истории из 5000 реальных матчей, которые модель не видела при обучении. Результаты подтвердили жизнеспособность гибридного подхода:
- Базовый ELO (версия V1): показал точность около 64.2%.
- Чистый ML (XGBoost на глубоких признаках): дал точность около 67.5%.
- Гибридный бленд V2 (ML + Экспертный скоринг): показал точность 69.8%.
- Высокая уверенность (сигналы > 60%): точность прогнозов выросла до 76.5%.
Мой технологический стек
Всю систему я собрал как автономное веб-приложение:
- Backend (Node.js & Python): Express.js для API, Prisma ORM для работы с PostgreSQL, Axios и Cheerio для быстрого скрапинга live-статистики с TennisAbstract.
- Machine Learning: Python, XGBoost Classifier, Scikit-Learn и Pandas для обработки данных и работы моделей.
- Frontend (React): интерфейс на Vite с интерактивными радарами Recharts для визуализации сил игроков и стильным Tailwind CSS.