Машинное обучение на финансовых рынках: создание R&D-системы прогнозирования акций на базе LSTM-сетей
Классический технический анализ предлагает оценивать графики «глазами». Однако в долгосрочной перспективе ручной поиск закономерностей на финансовых рынках сталкивается с человеческим фактором и ограниченностью восприятия. В рамках нашей R&D-лаборатории мы разработали собственную предиктивную систему анализа акций, основанную на машинном обучении, чтобы проверить: можно ли стабильно выделять чистые сигналы из рыночного шума.

Постановка задачи и философия проекта
Главная идея эксперимента состояла в том, чтобы уйти от субъективной оценки графиков. Вместо этого мы решили построить модель машинного обучения, которая оценивает рынок по широкому спектру факторов и выдает математически обоснованную вероятность движения цены — вверх или вниз.
На практике задача оказалась значительно сложнее стандартного скрипта с парой технических индикаторов. Для получения качественного прогноза потребовалось спроектировать полноценный многоуровневый конвейер данных (Data Pipeline).
Сырые данные → Проектирование признаков (Feature Engineering) → Ансамбль ML-моделей → Прогноз → Историческое тестирование (Backtesting)
Проектирование признаков (Feature Engineering)
Модель обучалась на комплексе признаков, описывающих состояние рынка с разных сторон:
- Тренд: Экспоненциальные и простые скользящие средние (EMA, SMA) для определения глобального направления движения.
- Волатильность: Средний истинный диапазон (ATR) для оценки текущей изменчивости и фильтрации шума.
- Перекупленность и перепроданность: Индекс относительной силы (RSI) как индикатор зон экстремальных значений.
- Отклонения: Линии Боллинджера (Bollinger Bands) для фиксации аномальных отклонений от среднего.
- Уровни поддержки и сопротивления: Сетка Фибоначчи для автоматического вычисления ключевых ценовых уровней.
- Динамика: Логарифмическая доходность (Log Returns) для нормирования изменений цен во времени.
- Макро-факторы: Интеграция новостного фона и динамики поведения смежных секторов рынка для учета контекста.
Архитектура системы: Ансамбль моделей на базе LSTM
Для обучения моделей использовалась детальная 5-летняя историческая глубина рынка. Простые алгоритмы классификации плохо работают со временными последовательностями, поэтому ядро системы было реализовано в виде ансамбля из двух моделей:
- Пространственная модель: Оценивает текущие срезы рыночных факторов и ищет взаимосвязи между признаками в моменте.
- Временная модель (LSTM): Архитектура Long Short-Term Memory (длинная краткосрочная память) специализируется на обработке временных рядов. Она отслеживает последовательности движений цен и запоминает предысторию поведения актива.
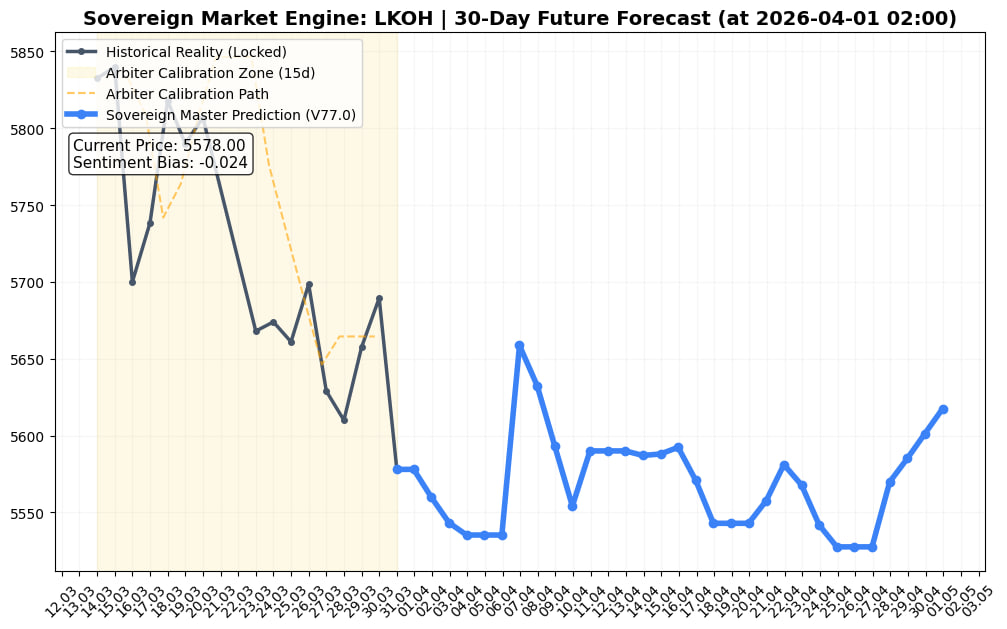
Валидация, бэктесты и результаты
Чтобы исключить эффект подгонки под исторические данные (overfitting), система проходит жесткий процесс валидации:
- Полноценный бэктестинг (Backtesting) на исторических данных, не участвовавших в обучении.
- Эмуляция реальной торговли с учетом проскальзываний и комиссий брокера.
- Поиск рыночных аномалий и сопоставление прогнозов с фактической траекторией движения активов.
График: Пример отработки предиктивной модели на исторических данных и сравнение прогнозной траектории с реальным графиком цены.
Ключевые выводы
Этот R&D проект отлично иллюстрирует реалии разработки современных систем искусственного интеллекта. Генеративные модели (AI) могут помочь написать отдельный кусок кода или оптимизировать функцию. Но собрать такую систему целиком, спроектировать пайплайны данных, настроить валидацию и связать разрозненные модули в единый стабильно работающий организм — это сложная инженерная задача, требующая классического опыта системного разработчика.
В дальнейших планах нашей лаборатории — исследование зон эффективности модели (где алгоритм дает наиболее точные сигналы) и детальный разбор условий, при которых происходят ложные срабатывания.